The above code is not working :(
Not many can claim 25 years on the Internet! Join us in celebrating this milestone. Learn more about our history, and thank you for being a part of our community!
I've missed a <= instead a <.
So the fix should be:
unsigned int w = x1 - x0 + 1; // width of rectangle
unsigned int h = y1 - y0 + 1; // height

Many thanks..
No next step..
Can you explain in plain words, what does nVidia do with their bin rasterizer algorithm ? Is it easy to implement ?
Which is easier, your algorithm with sorting that you proposed? Can I get better performance ?
That's very complex, thus much harder to implement, but much faster for sure. Maybe my proposal is similar to the former ‘FreePipe’ work they mention.
The next step would be the work on binning or sorting. Both is often a building block for more advanced algorithms like these. They rely on binning, for example.
Binning also is often used to bin lights to tiles in screenspace, so many lights can be processed efficiently. That's maybe an application to search for examples.
Sorting on the other hand would give better results, actually perfect results for my proposal.
But sorting is more expensive, and i could not suggest which is probably the better option.
I guess you also need to spend more work on clipping. That's quite complex too. A guard band is often used for compromise, to reduce the amount of new, clipped geometry to be generated. Triangles covering the guard band then need to be clipped to the actual screen per scanline, pixel or bounding rectangle by the rasterizer. I assume your approach already (but only) supports that latter case of clipping the bounding rectangle.
But many triangles can't be represented with a guard band. For example, triangles which have vertices behind the camera can't be projected to screenspace at all. We must clip their geometry before the projection. This complicates stuff a lot.
Because clipping causes new triangles, we do not know in advance how many triangles we get. Which again complicates things, usually solved by using memory buffers ‘probably’ large enough in practice. If we exceed this, we get artifacts, but at least we should make sure the application does not crash.
That's a lot of work. Maybe the hardest part, as i remember it from work on CPU rasterization.
I would like to apply your idea of sorting the triangles, but don't know how would the buffer look like, and submitting the ids.. could you formulate your algorithm a bit more in details ? for example what is IF (survive)
Many thanks for your collabration and your work!
I see i had a bug there:
for each triangle
{
transform vertices, frustum and backface culling.
If (survives)
{
CalculateClippedBoundingRectangle(triangle);
//uint key = (retangleArea<<32) | triangleIndex; // i had 64 bit key in mind, but it's 32, so a left shift of 32 would make the area vanish
uint key = (rectangleArea<<16) | triangleIndex;
buffer.Append(key);
}
}If (survives) means that the triangle is not culled.
I proposed to combine this kernel with frustum and back face culling. For your current scene and camera setup, you would need only back face culling.
Frustum culling is related to clipping, so you could care about that later.
The key does bitpacking to store both the area and the index. Because we want to sort by area, area must take the highest bits.
After the sorting is done, you need to unpack the bits to get the triangle index by index = key & 0xffff; Of course you decide how many bits you need.
Cuda has optimized libraries for sorting. I guess this exists for OpenCL too and could be found on github or libraries offered from GPU vendors.
Appending to a buffer is most easy using atomicAdd.
We have a global variable in vram, e.g. in a small buffer. Having forgotten syntax, i call this global int (still very much pseudo code):
// global data
global int bufferIndex = 0;
// kernel...
int index = atomicAdd(bufferIndex, 1);
buffer[index] = key;However, this is not great because it causes atomic access from all threads to the same memory address.
So after this works, you can optimize by using a small buffer in LDS memory per workgroup. You fill it the same way, but now we only need atomicAdd to a counter in LDS memory, which is very fast.
Only after this local buffer is full, you do one atomicAdd to the global index with the local buffer size. This reserves space so all threads can then just copy the local LDS buffer to the global VRAM buffer. Then we st local counter to zero and start filling the same local buffer again.
That's an important optimization we can use very often, but not yet needed to make it work.
… a never ending stream of details … ; )
I understand the approach, but don't know why it would make a difference.
We will sort by area, so small triangles are rendered first then big ones afterwards, right ?
how would that optimize the performance ?
AhmedSaleh said:
how would that optimize the performance ?
The problem is similar to the nested loop being bad for GPU.
Imagine thread 1 draws a triangle with 10 pixels.
Thread 2 draws triangle with 100 pixels.
Even with the optimized loop of today, thread 2 will ‘throttle’ thread 1.
All threads of a workgroup (or wave / warp to be precise) will go idle and do nothing until the one thread which has the largest triangle is done.
That's the problem i aim to solve by sorting. After sorting, triangle areas of our list will be like:
2,2,2,3,4,4,5,7,…
A workgroup will take a sequence of small size from that list, e.g. the sequence 2,2,2,3 if a warp would be only 4 threads wide.
Thus all threads of the warp will finish at roughly the same time, and will be instantly ready for new work.
Or in other words: All threads of the entire GPU will do work most of the time, instead waiting.
If we don't sort, the sequence may be 2,7,3,4. This means 3 threads will wait half of the time, so we achieve utilization of only 25%.
This is what makes the ‘many threads in lockstep’ execution model of GPUs so different from CPU multi threading. It is often hard to saturate a GPU and utilize its potential, requiring completely different algorithms.
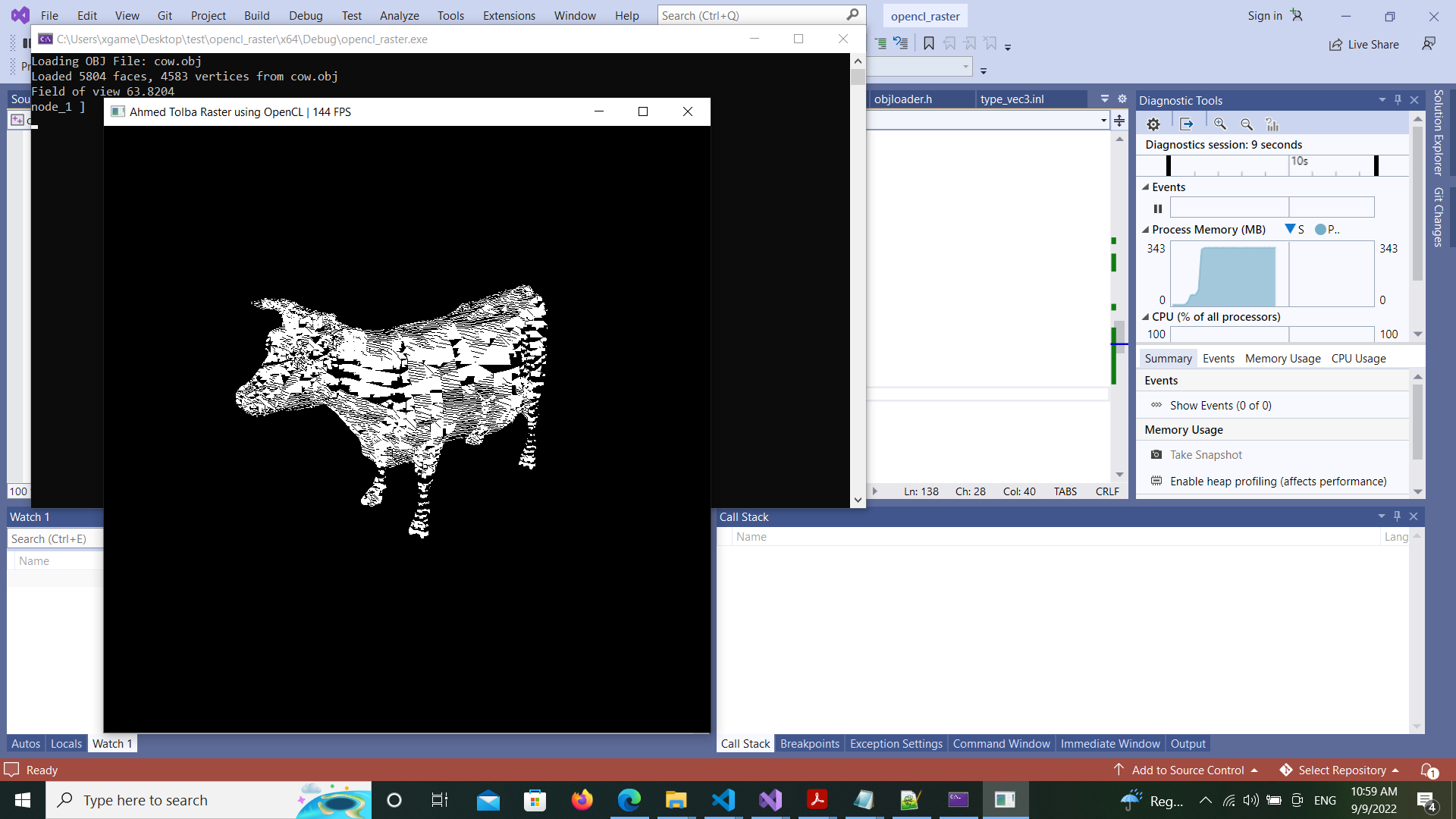
Here is the final rasterizer with shading and color/normals interpolation without back face culling and depth buffer,, will add them later..
I will try your idea, but there is on major problem, my current platform doesn't support Atomic operations, is there a way to overcome adding atomically on the buffer ?







